
이 모델은 113개의 프레임으로 구성된 비디오를 생성하고 24 FPS로 렌더링할 수 있습니다.
엔비디아 연구팀은 고품질 비디오 합성을 위한 새로운 스테이블 디퓨전 기반 모델을 도입하여 사용자가 텍스트 프롬프트를 기반으로 짧은 비디오를 생성할 수 있도록 했습니다. Latent diffusion 모델을 기반으로 하는 이 모델은 압축된 저차원 잠재 공간에서 훈련되어 과도한 컴퓨팅 수요를 피할 수 있으며, 1280×2048 해상도로 113프레임 길이의 비디오를 생성하고 24FPS로 렌더링하여 4.7초 길이의 클립을 생성할 수 있습니다.

“특히 리소스 집약적인 작업인 고해상도 비디오 생성에 LDM 패러다임을 적용했습니다.”라고 개발팀은 설명합니다. “먼저 이미지에만 LDM을 사전 학습시킨 다음, 잠재 공간 확산 모델에 시간적 차원을 도입하고 인코딩된 이미지 시퀀스, 즉 비디오에 대한 미세 조정을 통해 이미지 생성기를 비디오 생성기로 전환합니다. 마찬가지로 확산 모델 업샘플러를 시간적으로 정렬하여 시간적으로 일관된 비디오 초고해상도 모델로 전환합니다.”
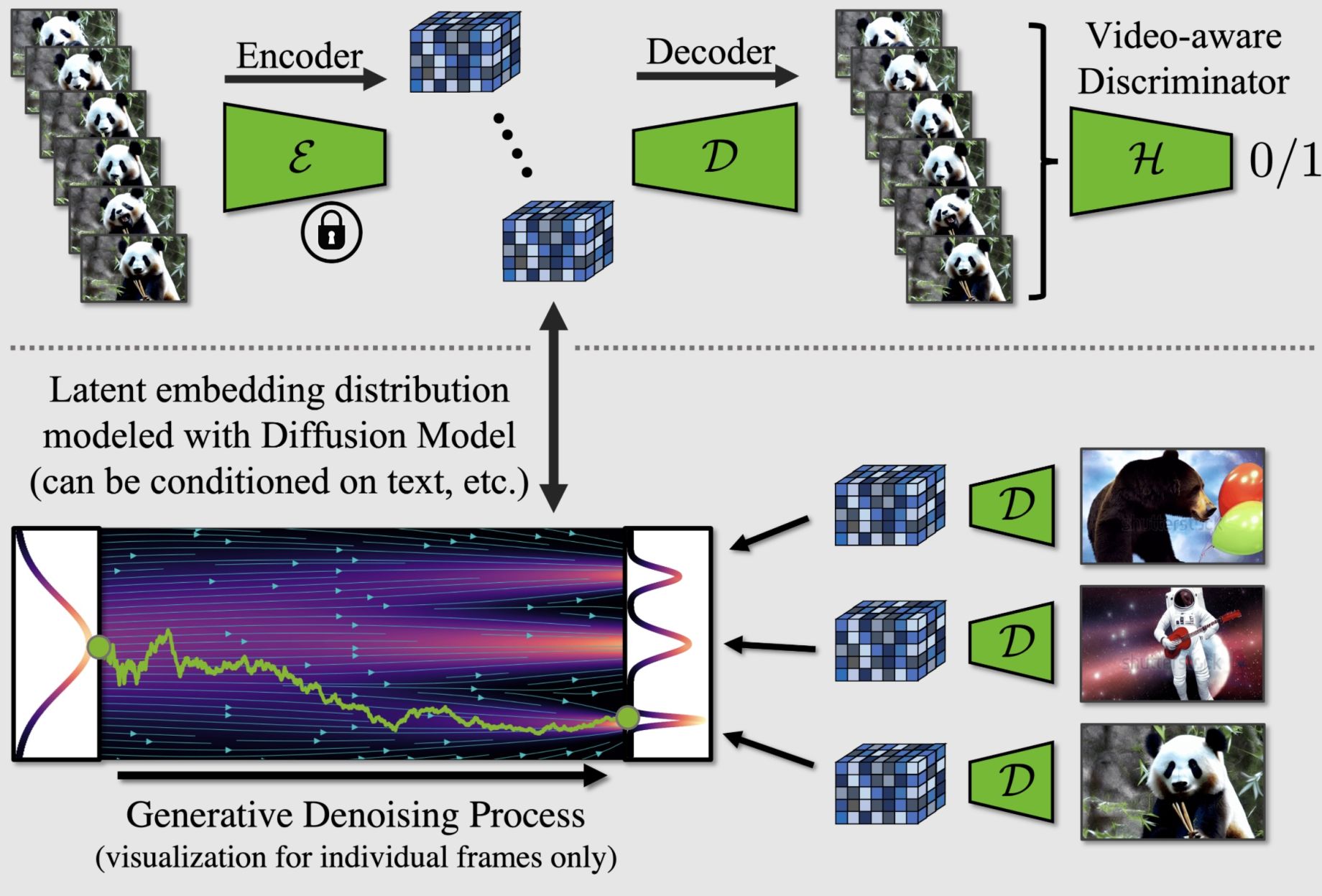
“이 경우 시간적 정렬 모델만 훈련하면 되기 때문에 우리의 접근 방식은 기성품으로 미리 훈련된 이미지 LDM을 쉽게 활용할 수 있습니다. 이를 통해 공개적으로 사용 가능한 최첨단 텍스트-이미지 LDM Stable Diffusion을 최대 1280 x 2048 해상도의 효율적이고 표현력 있는 텍스트-비디오 모델로 전환합니다. 이러한 방식으로 훈련된 템포럴 레이어가 다양한 미세 조정 텍스트-이미지 LDM으로 일반화됨을 보여줍니다. 이 속성을 활용하여 개인화된 텍스트-비디오 생성을 위한 첫 번째 결과를 보여줌으로써 향후 콘텐츠 제작에 대한 흥미로운 방향을 제시합니다.”

이 링크를 클릭하면 연구 논문 전문을 읽고 NVIDIA가 공유한 더 많은 결과를 확인할 수 있습니다.
혁명이 다가오고 있다.
오직 상상력만으로 명화를 그리고 글을 쓰고 곡을 만들고 프로그래밍 할 수 있는 격변의 시기!
생성 AI로 세계를 바꾸자.
당신이 좋아할만한 글:
 stable diffusion과 multiControlNet을 이용하여 실제 사람의 춤을 애니메이션으로 전환
stable diffusion과 multiControlNet을 이용하여 실제 사람의 춤을 애니메이션으로 전환
 Stability AI, StableLM 출시
Stability AI, StableLM 출시
 NVIDIA, NeMo 가드레일 발표
NVIDIA, NeMo 가드레일 발표
 NVIDIA, Inflection AI, Chegg, 삼성에서 AI 관련 큰 발표가 있었습니다.
NVIDIA, Inflection AI, Chegg, 삼성에서 AI 관련 큰 발표가 있었습니다.
 빌게이츠와 구글, 어도비, NVIDIA의 AI 소식
빌게이츠와 구글, 어도비, NVIDIA의 AI 소식
 Stability AI, SDXL 출시
Stability AI, SDXL 출시
 텍스트를 올바르게 렌더링할 수 있는 텍스트-이미지 변환 모델을 출시하는 Stability AI
텍스트를 올바르게 렌더링할 수 있는 텍스트-이미지 변환 모델을 출시하는 Stability AI
 Stability AI, 개발자를 위한 강력한 텍스트-애니메이션 툴 Stable Animation SDK 출시
Stability AI, 개발자를 위한 강력한 텍스트-애니메이션 툴 Stable Animation SDK 출시